Thuật toán BERT của Google thực sự là gì? Cách hoạt động của nó như thế nào và ảnh hưởng như thế nào đến kết quá tìm kiếm. Dựa vào đó tối ưu bài viết của mình như thế nào?
BERT là bản cập nhật vào cuối năm 2019, có tác động đến 10% trên tổng truy vấn. Nó cũng sẽ có ảnh hưởng đến thứ hạng tự nhiên và cả các đoạn trích nổi bật (TOP 0). Vì vậy, bản cập nhật không phải là một sự thay đổi nhỏ. Và bài viết sau, Lưu Anh Media sẽ giải thích chi tiết thuật toán này.
BERT trong tìm kiếm là gì?
BERT là từ viết tắt của Bidirectional Encoder Representations from Transformers.
Nói một cách đơn giản, BERT của Google giúp bộ máy của google hiểu rõ hơn về sắc thái, ngữ cảnh của các từ trong Search và đưa ra những kết quả tốt nhất, hữu ích nhất cho người dùng.
BERT giúp giải quyết những thách thức nào?
Có những thứ mà con người có thể hiểu một cách dễ dàng nhưng với máy móc thì không phải bao giờ cũng như thế.
Vấn đề về từ ngữ
Có nhiều từ ngữ không rõ ràng, có nhiều nghĩa và đồng nghĩa nên máy móc rất khó để phân biệt.
Thuật toán BERT được thiết kế để giúp giải quyết những câu, cụm từ mơ hồ được tạo thành từ những từ có nhiều nghĩa.
Sự mơ hồ và đa nghĩa
Kể cả Tiếng Việt cũng như Tiếng Anh, hầu hết các từ đều có nhiều nghĩa. Trong văn nói thì nó còn phức tạp hơn vì còn những từ đồng âm.
Ví dụ: “Em cao bao nhiêu?” và “Em K bao nhiêu?” (K được nhiều người gọi tắt là Khóa trong năm học)
Việc nhận thức những câu nói này không quá khó đối với con người vì chúng ta có nhận thức và ngữ cảnh cụ thể để hiểu. Nhưng với những công cụ tìm kiếm, máy móc thì không.
Đây là một trở ngại đối với việc tìm kiếm bằng giọng nói trong tương lai.
Ngữ cảnh của Word
Ludwig Wittgenstein – Nhà Triết gia đã nói rằng: “The meaning of a word is its use in a language.” Có nghĩa rằng: “Ý nghĩa của một từ là việc sử dụng nó trong một ngôn ngữ.”
Về cơ bản, điều này có nghĩa là một từ không có nghĩa trừ khi nó được sử dụng trong một ngữ cảnh cụ thể.
Nghĩa của một từ phụ thuộc vào nghĩa của những từ xung quanh nó.
Ví dụ: “I like the way that looks like the other one”
2 Từ like mang 2 nghĩa khác nhau. từ thứ nhất mang nghĩa là “thích” còn từ thứ 2 mang nghĩa là “giống như”.
Câu càng dài, càng khó để máy tính hiểu rõ được nghĩa của tất các các thành phần của câu.
Xem thêm: Anchor Text là 1 yếu tốt xếp hạng quan trọng của Google
Về NLR và NLU
NLR (Natural Language Recognition) không phải là hiểu.
NLR là một từ viết tắt tiếng anh có nghĩa nhận biết ngôn ngữ tự nhiên.
Ở đây sự hiểu biết về ngôn ngữ tự nhiên đòi hỏi phải có hiểu biết về ngữ cảnh và suy luận. Việc này khá dễ đối với con người. Tuy nhiên đối với máy móc thì rất khó.
NLU (Natural Language Understanding) không phải là Structured Data
Dữ liệu có cấu trúc (Structured Data) giúp phân biệt rõ ràng nhưng còn các bước trung gian phức tạp ở giữa thì sao?
Ở đây, dữ liệu có cấu trúc được sử dụng để giúp các công cụ tìm kiếm hiểu rõ hơn nội dung trang của bạn. Nhưng hiểu ngôn ngữ tự nhiên là một phần trung gian trong quá trình giúp công cụ hiểu về trang của bạn. NLU (hiểu ngôn ngữ tự nhiên) sẽ nhận biết và truyền thông tin dến Dữ liệu có cấu trúc để xử lý.
Không phải tất cả mọi người hoặc sự việc đều được phản ánh tới Sơ đồ tri thức
Sẽ vẫn còn rất nhiều khoảng trống cần lấp đầy (Các bước trung gian chưa được thực hiện).

Như bạn có thể thấy ở đây, chúng ta có tất cả các thực thể này và mối quan hệ giữa chúng. Đây là lúc NLU đi vào vì nó có nhiệm vụ giúp các công cụ tìm kiếm lấp đầy khoảng trống giữa các thực thể được đặt tên.
Xem thêm: 8 Kĩ thuật On – Page mà Google cho vào danh sách đen
Làm thế nào Công cụ Tìm kiếm có thể lấp đầy khoảng trống giữa các thực thể được đặt tên?
Phân biệt ngôn ngữ tự nhiên (NLD)
“You shall know a word by the company it keeps.” – John Rupert Firth, Linguist, 1957.
Cách từ hiện diện cùng nhau được kết nối mạnh mẽ:
- Đồng xuất hiện.
- Đồng xuất hiện trong cùng ngữ cảnh.
- Đồng thời xảy ra thay đổi nghĩa của từ.
- Những từ chia sẻ những người hàng xóm tương tự cũng được kết nối mạnh mẽ.
- Sự tương đồng và liên quan.
Các mô hình ngôn ngữ được tạo trên kho ngữ liệu văn bản rất lớn hoặc bộ sưu tập vô số từ để tìm hiểu sự tương đồng về phân phối và xây dựng các mô hình không gian vecto để nhúng từ.
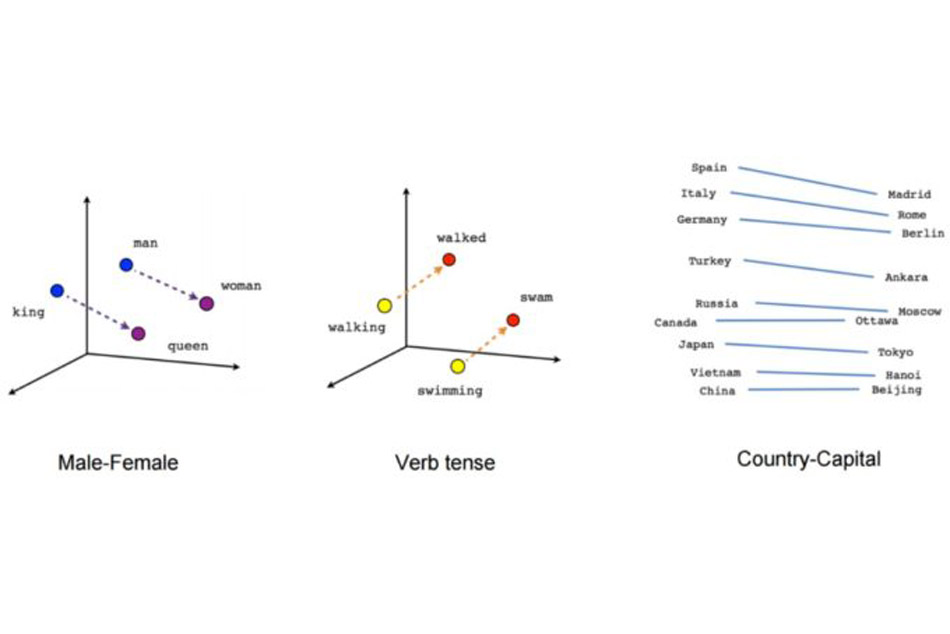
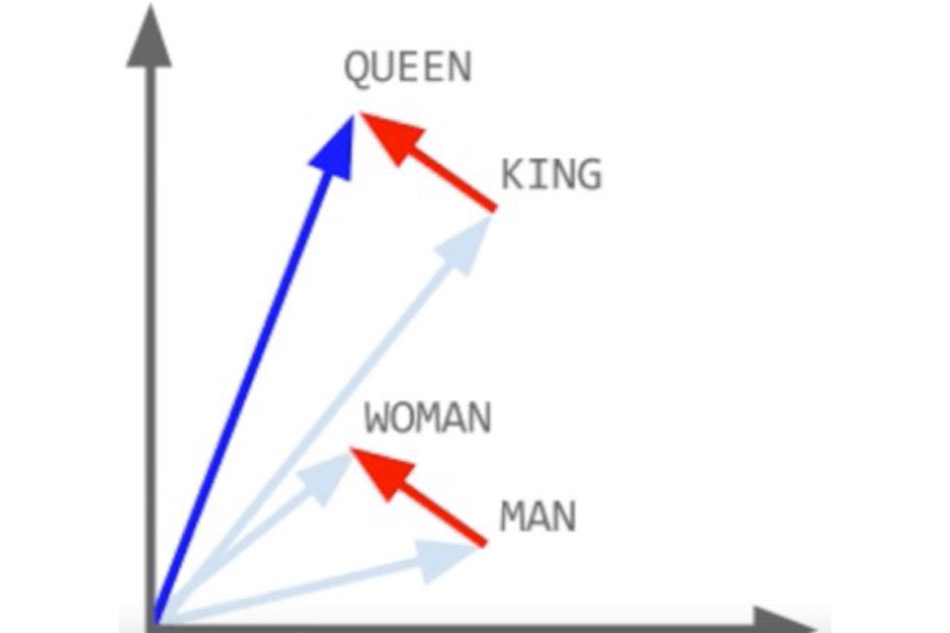
Các mô hình NLP tìm hiểu trọng số của khoảng cách tương tự và liên quan. Nhưng ngay cả khi chúng ta hiểu bản thân thực thể (sự vật), chúng ta cần hiểu ngữ cảnh của từ.
Về bản chất, các từ đơn không có ý nghĩa ngữ nghĩa nên chúng cần gắn kết với văn bản. Sự liên kết là sự liên kết ngữ pháp và từ vựng trong một văn bản hoặc câu để kết nối một văn bản lại với nhau và mang lại ý nghĩa cho nó.
Nếu không có các từ xong quanh thì một từ khó có thể có nghĩa trong câu.
Một phần quan trọng của việc này là gắn thẻ Part-Of-Speech (POS):
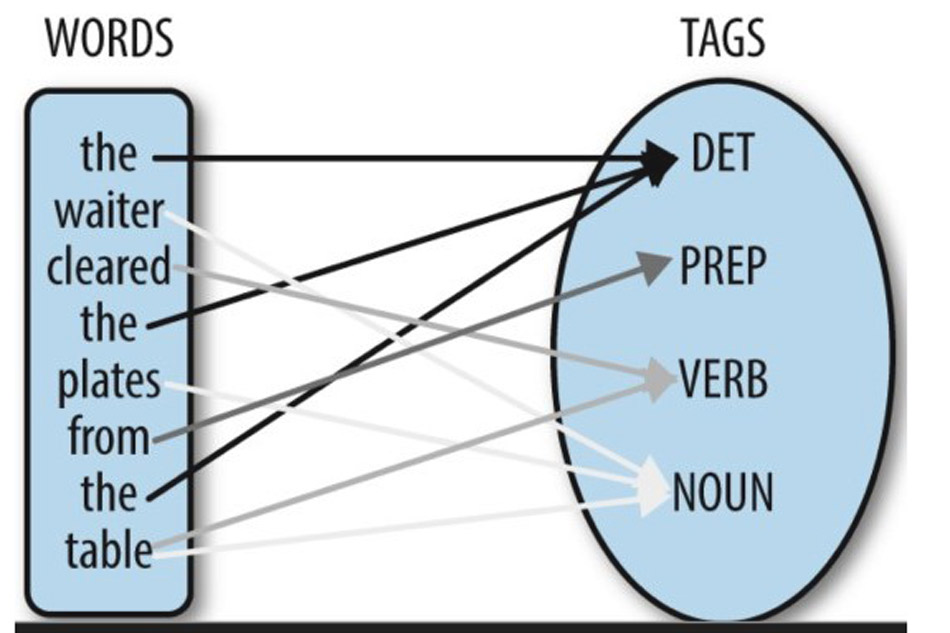
Xem thêm: GOOGLE UPDATES – LỊCH SỬ CẬP NHẬT THUẬT TOÁN CỦA GOOGLE
Cách hoạt động của BERT
Các mô hình ngôn ngữ trước đây (chẳng hạn như Word2Vec và Glove2Vec) đã xây dựng tính năng nhúng từ không theo ngữ cảnh.Còn đối với BERT thì cung cấp “ngữ cảnh”.
B: Bi-directional (2 chiều)
Trước đây, tất cả các mô hình ngôn ngữ (ví dụ: Skip-gram và Continuous Bag of Words) là một chiều nên chúng chỉ có thể di chuyển cửa sổ ngữ cảnh theo một hướng – một cửa sổ di chuyển của “n” từ (sang trái hoặc phải của từ đích) để hiểu ngữ cảnh của từ.
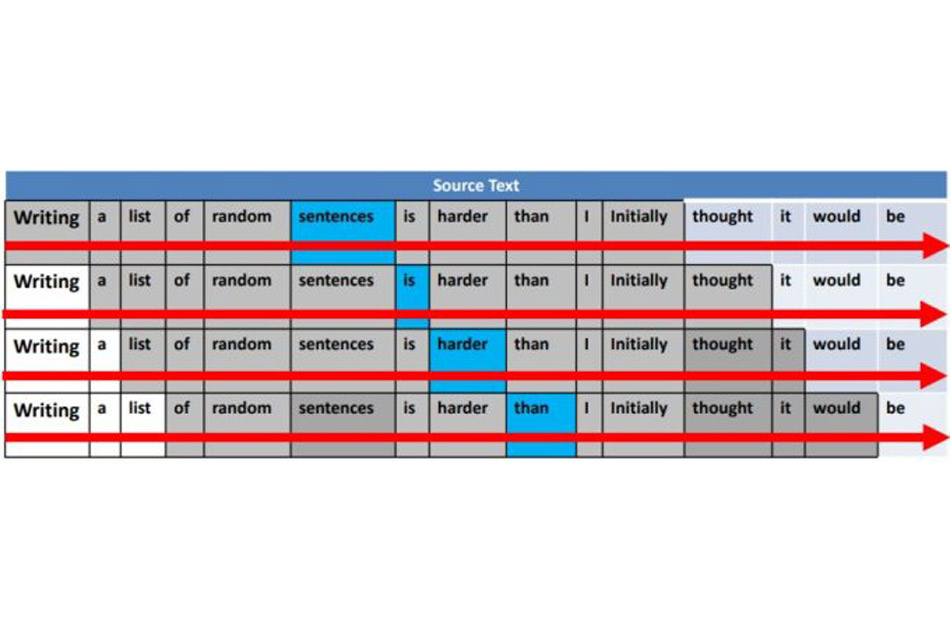
Tức là những từ sau sẽ được hiểu thông qua những từ đằng trước trong câu nhưng nhưng không có chiều ngược lại. Những từ đằng sau không có bổ trợ để dịch những từ đằng trước.
Hầu hết các trình mô hình hóa ngôn ngữ là đơn hướng. Họ có thể duyệt qua cửa sổ ngữ cảnh của từ chỉ từ trái sang phải hoặc từ phải sang trái. Chỉ theo một hướng, nhưng không phải cả hai cùng một lúc.
Còn đối với BERT thì khác. BERT sử dụng mô hình ngôn ngữ 2 chiều.

BERT có thể thấy toàn bộ câu ở hai bên của mô hình ngôn ngữ theo ngữ cảnh từ và tất cả các từ gần như cùng một lúc.
ER: Encoder Representations (Bộ mã hóa)
Những gì được mã hóa sẽ được giải mã. Đó là một cơ chế vào và ra.
T: Transformers
BERT sử dụng “transformers” và “masked language modeling (Mô hình hóa ngôn ngữ được che dấu)”.
Một trong những vấn đề lớn đối với việc hiểu ngôn ngữ tự nhiên trong quá khứ là không thể hiểu ngữ cảnh mà một từ đang đề cập đến.
Đại từ là một ví dụ. Rất dễ mất dấu ai đó đang nói về ai trong một cuộc trò chuyện. Ngay cả con người đôi khi cũng không rõ ai đó đang được nhắc đến trong một cuộc trò chuyện mọi lúc.
Điều đó tương tự đối với các công cụ tìm kiếm, chúng khó theo dõi khi bạn nói anh ấy, họ, cô ấy, chúng tôi, nó, v.v.
Vì vậy, người điều khiển cần thực sự tập trung vào các đại từ và tất cả các nghĩa của từ đi cùng nhau để cố gắng ràng buộc người đang được nói chuyện hoặc điều đang được nói đến trong bất kỳ ngữ cảnh nhất định nào.
Mô hình ngôn ngữ được che giấu sẽ ngăn không cho từ được nói đến xuất hiện lần 2. Sự che dấu này là cần thiết vì nó ngăn không cho từ được nhấn mạnh xuất hiện lần 2.
Khi sự che dấu xuất hiện, BERT chỉ cần đoán xem từ được bỏ qua là gì. Đó cũng là một phần của quá trình cải tiến giúp bộ máy tốt hơn.
BERT giúp gì cho các loại nhiệm vụ của ngôn ngữ tự nhiên?
BERT sẽ trợ giúp những việc như:
- Xác định thực thể được đặt tên.
- Dự đoán câu tiếp theo theo văn bản.
- Đối tượng, sự vật chính được nhắc tới.
- Trả lời câu hỏi.
- Định nghĩa từ ngữ.
- Tóm tắt tự động.
- Nghĩa của 1 từ trong đoạn văn của môt từ nhiều nghĩa.
BERT đã nâng cao tiêu chuẩn state-of-the-art (SOTA: mức hiện đại) trên 11 nhiệm vụ của NLP.
BERT sẽ tác động đến tìm kiếm như thế nào?
BERT sẽ giúp Google hiểu ngôn ngữ con người tốt hơn
Sự hiểu biết của BERT về các sắc thái của ngôn ngữ con người sẽ tạo ra sự khác biệt lớn về cách Google diễn giải các truy vấn bởi vì mọi người đang tìm kiếm rõ ràng với các truy vấn dài hơn, nhiều câu hỏi.
BERT sẽ giúp mở rộng tìm kiếm bằng giọng nói
BERT cũng sẽ có tác động lớn đến tìm kiếm bằng giọng nói.
Mong đợi những bước nhảy vọt cho SEO quốc tế
BERT có khả năng từ đơn ngôn ngữ đến đa ngôn ngữ bởi vì rất nhiều mẫu trong một ngôn ngữ được dịch sang các ngôn ngữ khác.
Có khả năng chuyển nhiều nội dung học sang các ngôn ngữ khác nhau mặc dù bản thân nó không nhất thiết phải hiểu đầy đủ về ngôn ngữ đó.
Google sẽ hiểu rõ hơn về “Contextual Nuance (Sắc thái theo ngữ cảnh)” bà các truy vấn không rõ ràng
Rất nhiều người đã phàn nàn rằng thứ hạng của họ đã bị ảnh hưởng.
Nhưng tôi nghĩ rằng điều đó có lẽ vì Google theo một cách nào đó đã hiểu rõ hơn sắc thái trong ngữ cảnh của các truy vấn và sắc thái ngữ cảnh của nội dung và điều chỉnh lại thứ hạng.
Bạn có nên (hoặc Bạn có thể) Tối ưu hóa Nội dung của mình cho BERT không?
Có lẽ là không.
Google BERT là một khuôn khổ để hiểu rõ hơn. Nó không đánh giá nội dung. Nó chỉ hiểu rõ hơn những gì nội dung nói tới.
Ví dụ: Google Bert có thể đột nhiên hiểu nhiều hơn. Có thể có những trang web được tối ưu hóa quá mức có thể đột nhiên bị ảnh hưởng bởi thứ khác như Panda vì BERT của Google đột nhiên nhận ra rằng một trang cụ thể không liên quan đến một thứ gì đó.
Điều đó không có nghĩa là bạn đang tối ưu hóa cho BERT, có lẽ bạn chỉ nên viết tự nhiên ngay từ đầu.

